Linked list is one of the first data structure that you learn when you start reading about data structure.
Linked List has its own advantage over other data structure like array, just to recap few of them
Some benefit of Linked List
- Insert cost is low, just update address of new node
- Memory Allocation cost is very low because it has to just allocate one node and attach it to last node
- Very good data structure when you don't know how much data you will be storing, it grow on need basis, no wastage of space
- Very low overhead when element is removed.
Things that are not good about Linked List
- Access by Index is bad and not recommended .
- Creates lot of work for Garbage Collector, can result in frequent Minor GC due which young objects will be promoted early to old generation
- Extra Node Object is required for each element , so total memory required is (Node+Value) * No Of Objects. This can become problem if there is lot of objects.
- Random memory access because of the way nodes are linked, this is major draw back because random memory walk is slow as compared to linear walk, CPU does lot of hard work to optimized memory access but Linked List or Tree based Data Structure can't use all those optimization due to random memory walk.
On NUMA based machine it become worse.
Do we need Linked List now ?
That is really tough question to answer, but the way Linked List performs it looks like it has no space in Data Structure Library.
With the current In-Memory trend, where application is keeping all the data in memory and data structure like Linked List are not friendly for that.
Lets Tweak Linked List for today requirement.
So today we need Linked List that has advantage of both Linked List & Array, that way we can get best of both world.
For testing i will create MultiValueLinkedList that has feature of both array & linked list. So it is like each Node contains small Array List and all these nodes are linked.
So you can say Array List linked via Linked List.
For performance test i add some millions of items in Linked List/MultiValueLinkedList/Array List and iterate over it. I start with 10 Million element and increase it by 5 Million.
Add Performance
Lets look at some numbers for add operation in different types of list

X Axis - Time taken for add in Ms
Y Axis - No of Element added in Millions
MultiValueLinkedList is clear winner in this test, it is around 22X times faster than Linked List.
Linked List performance is so bad that graph scale is screwed up and it is difficult to make out difference between MultiValueLinkedList & Array List, so i will put another graph for MultiValueLinkedList & Array List
ArrayList Vs MultiValueLinkedList

This graph gives better understanding of performance of Array List & MultiValueLinkedList, new linked list is 2.7X times faster than Array List.
Iterate Performance
Look at iterate performance before i try to explain reason of performance boost

X Axis - Time taken for iterate/access in Ms
Y Axis - No of Element in Millions
As i said earlier that new Linked List will be hybrid one , it will take best from Linked List & Array List and this graph confirms that , it is somewhere in between Linked List & Array List.
MultiValueLinkedList is around 1X times faster than linked list
Garbage Collections
This test is all about allocation and will not be completed without GC activity graph, i want to put more GC observation but that will make this blog big, so i will put just one Visual GC graph
Visual GC Graph for Linked List

Visual GC Graph for MultiValueLinkedList
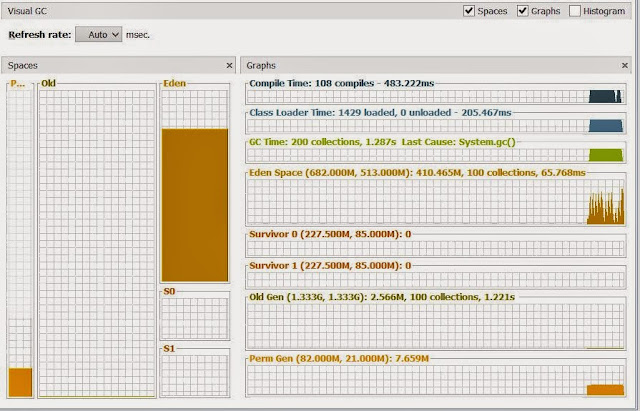
I don't have to explain much in these GC behavior, for Linked List minor GC activity is so much that object are promoted to old generation, all though it is not required.
GC behaves as expected for MultiValueLinkedList.
Observation
- Performance of add is best for MultiValueLinkedList & it is due to less number of allocation & almost no need to copy the Array as it is required for Array List whenever it grows
- Garbage produced by MultiValueLinkedList is very less. Memory usage of MultiValueLinkedList is same as ArrayList & for LinkedList it is double, that explains why we see object promotion to old generation.
- Iteration of MultiValueArrayList is slow as compared to Array List because memory access pattern is like Page by Page, it is possible to improve it further but adjusting the size of element in nodes.
Code is available @ github
Linked List has its own advantage over other data structure like array, just to recap few of them
Some benefit of Linked List
- Insert cost is low, just update address of new node
- Memory Allocation cost is very low because it has to just allocate one node and attach it to last node
- Very good data structure when you don't know how much data you will be storing, it grow on need basis, no wastage of space
- Very low overhead when element is removed.
Things that are not good about Linked List
- Access by Index is bad and not recommended .
- Creates lot of work for Garbage Collector, can result in frequent Minor GC due which young objects will be promoted early to old generation
- Extra Node Object is required for each element , so total memory required is (Node+Value) * No Of Objects. This can become problem if there is lot of objects.
- Random memory access because of the way nodes are linked, this is major draw back because random memory walk is slow as compared to linear walk, CPU does lot of hard work to optimized memory access but Linked List or Tree based Data Structure can't use all those optimization due to random memory walk.
On NUMA based machine it become worse.
Do we need Linked List now ?
That is really tough question to answer, but the way Linked List performs it looks like it has no space in Data Structure Library.
With the current In-Memory trend, where application is keeping all the data in memory and data structure like Linked List are not friendly for that.
Lets Tweak Linked List for today requirement.
So today we need Linked List that has advantage of both Linked List & Array, that way we can get best of both world.
For testing i will create MultiValueLinkedList that has feature of both array & linked list. So it is like each Node contains small Array List and all these nodes are linked.
So you can say Array List linked via Linked List.
For performance test i add some millions of items in Linked List/MultiValueLinkedList/Array List and iterate over it. I start with 10 Million element and increase it by 5 Million.
Add Performance
Lets look at some numbers for add operation in different types of list
Y Axis - No of Element added in Millions
MultiValueLinkedList is clear winner in this test, it is around 22X times faster than Linked List.
Linked List performance is so bad that graph scale is screwed up and it is difficult to make out difference between MultiValueLinkedList & Array List, so i will put another graph for MultiValueLinkedList & Array List
ArrayList Vs MultiValueLinkedList

This graph gives better understanding of performance of Array List & MultiValueLinkedList, new linked list is 2.7X times faster than Array List.
Iterate Performance
Look at iterate performance before i try to explain reason of performance boost

X Axis - Time taken for iterate/access in Ms
Y Axis - No of Element in Millions
As i said earlier that new Linked List will be hybrid one , it will take best from Linked List & Array List and this graph confirms that , it is somewhere in between Linked List & Array List.
MultiValueLinkedList is around 1X times faster than linked list
Garbage Collections
This test is all about allocation and will not be completed without GC activity graph, i want to put more GC observation but that will make this blog big, so i will put just one Visual GC graph
Visual GC Graph for Linked List

Visual GC Graph for MultiValueLinkedList

I don't have to explain much in these GC behavior, for Linked List minor GC activity is so much that object are promoted to old generation, all though it is not required.
GC behaves as expected for MultiValueLinkedList.
Observation
- Performance of add is best for MultiValueLinkedList & it is due to less number of allocation & almost no need to copy the Array as it is required for Array List whenever it grows
- Garbage produced by MultiValueLinkedList is very less. Memory usage of MultiValueLinkedList is same as ArrayList & for LinkedList it is double, that explains why we see object promotion to old generation.
- Iteration of MultiValueArrayList is slow as compared to Array List because memory access pattern is like Page by Page, it is possible to improve it further but adjusting the size of element in nodes.
Code is available @ github




